



Prognosis: Vulnerability Proliferation
With the increase of software usage worldwide, it’s only natural that a growing number of vulnerabilities will be discovered.
1999 was the inflection point for vulnerability listings. Prior to that, a variety of security tools offered different ways to categorize software security issues. As there was no standardized protocol for listing a vulnerability, inconsistencies were inevitable. In that year, the concept of common vulnerability and exposure (CVE) was introduced as a standard to represent software security flaws.
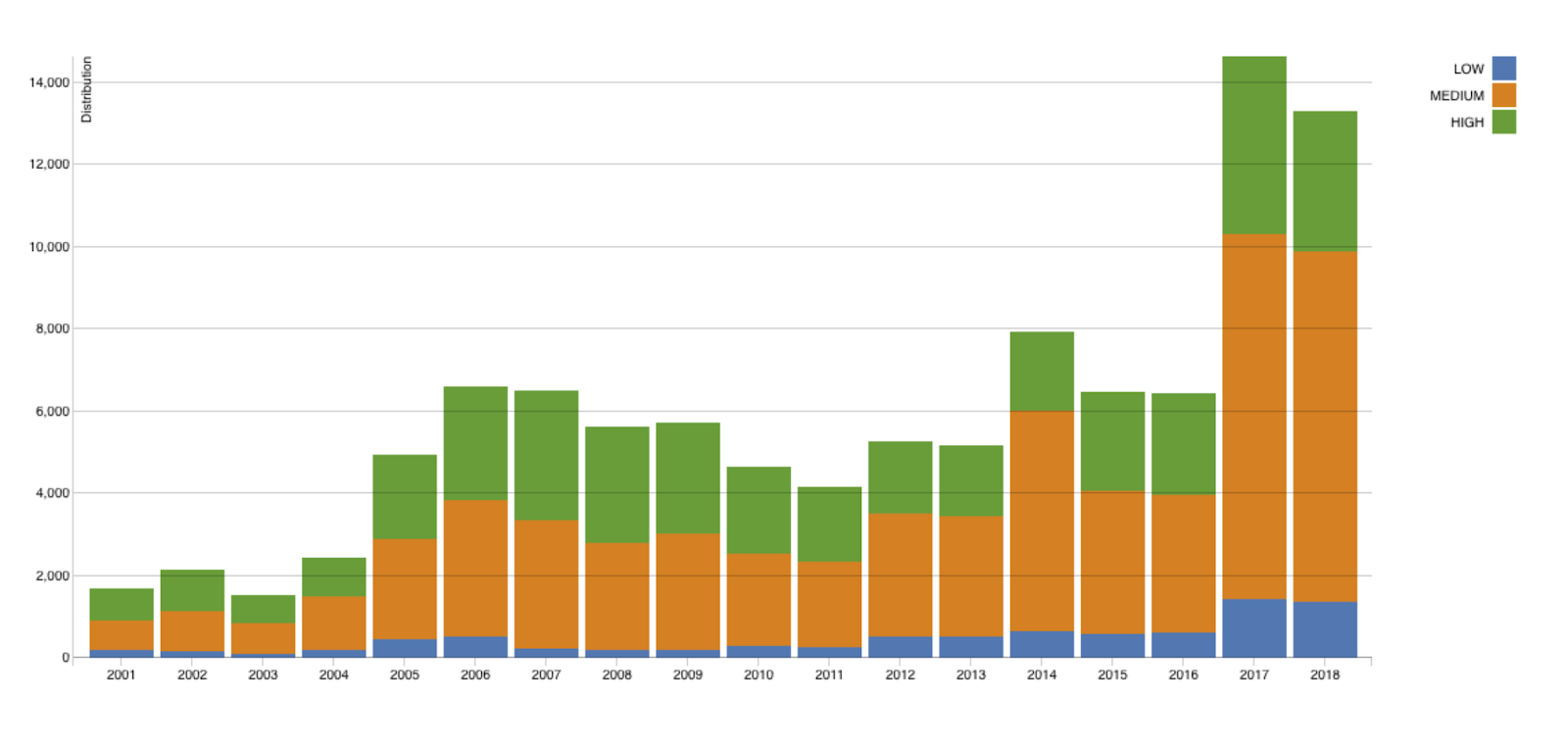
Since the original list of 321 CVEs was published in September 1999, there has been a growing number of vulnerabilities discovered on a monthly basis (figure 1). Today, with the rapid growth in software development and adoption, over 1000 vulnerabilities are disclosed every month. So far this year, a whopping 12,000 were received by NVD.
Figure 1 - Growth in CVEs discovered over the years (by NVD)
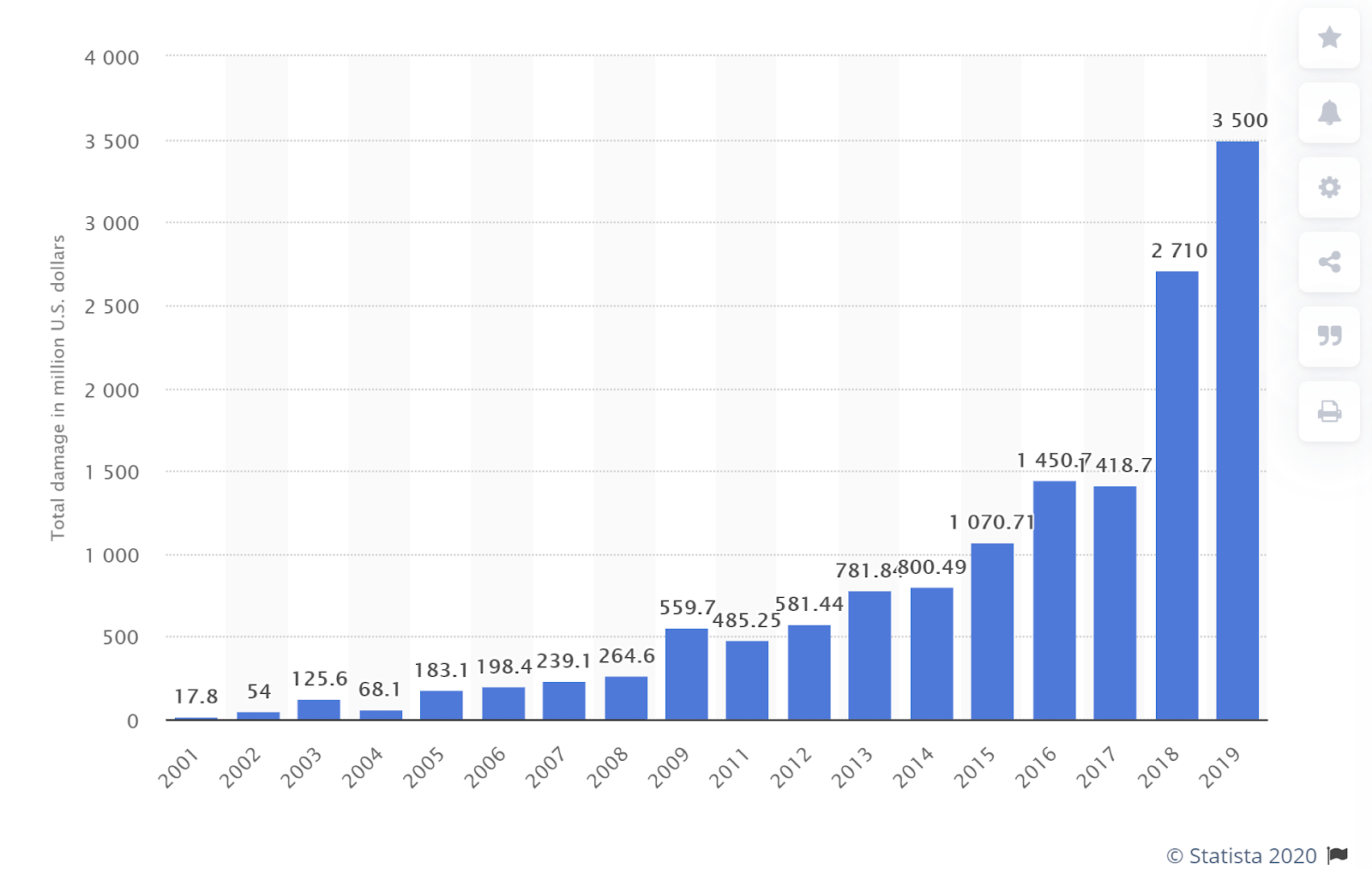
Hackers find a way to exploit these vulnerabilities, and the amount of monetary damage resulting from cyber crime grew from $17.8M in 2001 to $3500M in 2019 (figure 2).
Figure 2 - Amount of monetary damage caused by cyber crime to the IC3 from 2001 to 2019 (by Statista)
Cause for vulnerable software
Debates rage in developer circles over which coding languages are more secure than others (yes, they get heated! Imagine it like a meeting of the Avengers). But the one thing they agree on is that they can make any code insecure. It’s easy to play the villain in this scenario. (Some may argue this is the most natural outcome.)
Additionally, the increased demand of software coupled with shorter release cycles results in a greater number of applications released without completing a full analysis using available tools (SAST, DAST etc.).
Keep in mind that software companies cannot maintain older versions indefinitely. Leaving obsolete versions roaming around unmaintained is a good way to attract mice! They have to call the exterminators, fill out reports, etc. Work they certainly would be better off without.
Disclosing Vulnerabilities in Binary Code
Nowadays, there is limited access to source code within third-party software. This means that threat assessment must constantly be run to discover vulnerabilities in binary code.
With the growth in the number of software to test, we noticed shifts in the ways of discovering vulnerabilities. We saw innovative techniques to scale the manual, time-consuming process. Researchers are also searching for ways to apply machine learning algorithms to the process.
Manual Research
For a vulnerability researcher to discover flaws in a binary code, he needs to detect the execution flow and analyze the behavior of the program, i.e., searching for security bugs. For example, allocating a fixed sized buffer and then copying user controlled input into the allocated buffer might mean it can be exploited through a buffer overflow exploit.
This process, which requires reverse engineering the application using a debugger or a decompiler, is long and time-consuming. Therefore, techniques to scale it have been developed.
Useful tools
- Windows SysInternals - such as Process Monitor and Process Explorer
- Disassemblers - such as IDA and Radare
- Debuggers - such as OllyDbg, winDbg and x64dbg
Scaling the Process
Disclosing a mass of vulnerabilities using manual techniques requires a significant amount of time and human resources. Since we’re in a race to find these vulnerabilities before the attacker, we need some techniques to get across the finish line first. These tools can either fully discover vulnerabilities (yippee!) or hint at their existence (hurray!).
Static Binary Analysis Techniques
In order to scale the static binary analysis process, we use tools which model the assembly code and produce graphs for various features such as control-flow, data-flow, and control-dependence graphs. Then we compare these graphs with the observed pattern of vulnerabilities to detect them.
Useful tools
Static Binary Analysis using Angr
https://docs.angr.io/examples#vulnerability-discovery
Static Binary Analysis using Radare2
https://github.com/radareorg/radare2
Fuzzers
Fuzzing is an automated software testing technique. Fuzzers input a software with invalid, unexpected, and random data in order to detect its behavior. They look for exceptions such as crashes, failing built-in code assertions, or potential memory leaks.
Useful tools
AFL
OSS Fuzzing
https://github.com/google/oss-fuzz
CWEs
“Common Weakness Enumeration is a community-developed list of common software and hardware weakness types that have security ramifications”. “Weaknesses” are flaws, faults, bugs, vulnerabilities, or other errors in software or hardware implementation, code, design, or architecture that if left unaddressed could result in systems, networks, or hardware being vulnerable to attack.”(cwe official site)
Detecting CWE families helps analysts quickly find vulnerable code paths.
Useful tools
CWE Checker
https://github.com/fkie-cad/cwe_checker
Research on Applying Machine Learning Techniques
As we mentioned earlier, more than a thousand vulnerabilities are discovered every month. We believe that the numbers will grow higher in the future.
From the attacker point of view, it might be enough to find a few juicy exploitable vulnerabilities every now and then, but from the protection point of view, this assumption is far from the truth. To fully protect ourselves from cyber attacks, we need to find all the vulnerabilities that exist and identify them before the attacker does. The techniques and tools we mentioned above can scale the process and give vulnerability researchers hints, but there is still a gap to close for the process to be fully automated. Researchers worldwide are looking at applying machine learning techniques to the vulnerability discovery process. We found two interesting methods: detecting CWEs and feature extraction, both of which are open source code.
Detecting CWEs
Limitation of current CWE detection tools
Static binary analysis detects software weakness based on existing patterns. Generally, patterns are created by experts, and this requires time, effort, and cost, making it difficult to add and patch new patterns whenever an unknown vulnerability is encountered.
In the article “Instruction2vec: Efficient Preprocessor of Assembly Code to Detect Software Weakness with CNN” the researchers Yongjun Lee, Hyun Kwon , Sang-Hoon Choi, Seung-Ho Lim, Sung Hoon Baek and Ki-Woong Park propose a new method for detecting CWE. Their method is called instruction2vec—an improved static binary analysis technique that uses machine learning methods. Their framework consists of two steps: (1) it models assembly code efficiently using Instruction2vec, based on Word2vec; and (2) it learns the features of software weakness code using the feature extraction of Text-CNN without creating patterns or rules and detects new software weakness.
Research Implementation
Instruction2vec is a preprocessor that vectorizes the instructions of the assembly code. The output of Instruction2vec is a vector value that can be trained on various models. Instruction2vec has the following characteristics:
- Gives a vector value of fixed length
- Considers the syntax of the assembly code
- Works based on Word2vec
It can be found here.
Feature Extraction
In the article “Toward large-scale vulnerability discovery using machine learning” Grieco et al. proposed an approach that uses lightweight static and dynamic features, extracted from binary programs, to predict if a test case is likely to contain a software vulnerability using machine learning techniques.
The static features are the sequences of calls to the standard C library functions in the program. The dynamic features are extracted from analyzing the program execution traces that contain function calls and arguments.
They treat each call trace as a text document, allowing them to vectorize the data using text-mining techniques: N-grams and word2vec.
Research Implementation
VDiscover is a tool designed to train a vulnerability detection predictor. Given a vulnerability discovery procedure and a large enough number of training test cases, it extracts lightweight features to predict which test cases are potentially vulnerable.
VDiscover aims to be used when there are a large number of test cases to analyze using a costly vulnerability detection procedure. It can be trained to provide a quick prioritization of test cases. The extraction of features to perform a prediction is designed to be scalable.
There are two main components of the tool:
- fextractor: to extract dynamic and static features from test cases.
- vpredictor: to train a new vulnerability prediction model or predict using a previously trained one. It can be used to cluster and visualize a set of test cases.
It can be found here.
Machine Learning Challenges:
- Many tools can support source code but not binary code
- The binaries might be too large to be used for practical inspection
- The binaries may be obfuscated, which may cause invalid or inaccurate results
- Computationally expensive and impractical - analyzing binaries, whether statically or dynamically, requires complex computations and simulations to accurately identify potential bugs and threats
- Environmental and infrastructure requirements must be met, creating a challenge to simulate in a remote machine
- And more...
A cure for the ailment
As it’s widely known, vulnerability management tools that rely on CVEs have a built-in flaw: they cannot detect threats without a public disclosure. This calls for a much needed advancement—the ability to identify threats in compiled code on the customer side, despite the fact that the software is maintained, obsolete, and relatively unknown.
Vicarius’s TOPIA enables organizations to identify threats beforehand. It deconstructs installed software as the binary analysis engine hunts for security flaws compiled within. By comparing the binary pieces to existing threat categories, the solution notifies companies before an official CVE is published. Once a known threat exists within a given software, companies can harness the patchless protection technology to secure the outstanding threats.
The majority of the tech relies on disassembling compiled binaries, breaking them into code snippets and comparing the results to exploited code. The results indicate which potential threats exist inside a given application despite the existence of known vulnerabilities.
Authored by Roi Cohen and Shani Reiner (Dodge).
LIVE! On Security Weekly
Watch Roi and Shani demonstrate some of these techniques on Paul's Security Weekly! 😎
